A brief gander into Data Structures
Our first article in our new Data Structures Series

A data structure is simply a way to organise data while an algorithm gives us a way to exploit it
That’s the whole article summarised in one sentence.
Introduction
Data structures were originally created in the early days of computer science when we had two severe limitations.
The first was space.

Just look at this humongous machine that gives us a whooping …. 9mb of storage space in the 1960s. This cost probably a solid few million and was cutting edge tech in the day.
With space being a premium, it was necessary to develop methods to store data in order to best maximise the limited space that we had
After all, we couldn’t just declare a billion variables like we do today in python where everything is managed out of the box
The second was abstraction. By being able to define abstract data structures without going into detail about their specific implementations, we can utilise algorithms that take advantage of their structure to achieve the same task in a much faster manner.
One good way to therefore conceptualise of a data structure is a set of rules on which we need to adhere to when encoding and decoding data
For instance, instead of trying to find an algorithm that works on social networks to find the closest connection between two individuals, we can simply define it as a graph and utilise what is known as a Breadth-first search from one to another.
By abstracting away the minute and specific, we can achieve the same result in a much cleaner and efficient way.
Broad Categories
These are the rough categories of data structures that exist. There are specific and niche categories that exist for specific situations - even when it comes to sorting.

Let’s run through a few simple examples to see how we might be able to use different data structures for the same task and why one is preferable to another.
But before we do so, let’s start by defining three things - a quick model of how memory works in a computer, a variable and a method to compare algorithms.
Memory in a computer
While there are a lot of specific intricacies, we will stick to a more high level approach.
Memory is simply a large piece of storage broken down into small chunks. This overall chunk is commonly known as RAM ( Random Access Memory )
Let’s start by visualising our memory as these individual chunks of non-overlapping blocks that we can write values to.
Let’s also assume that we have written some form of data to these chunks of non-overlapping blocks - x,y and z. Let’s also assume that x, y and z all take up one block each.
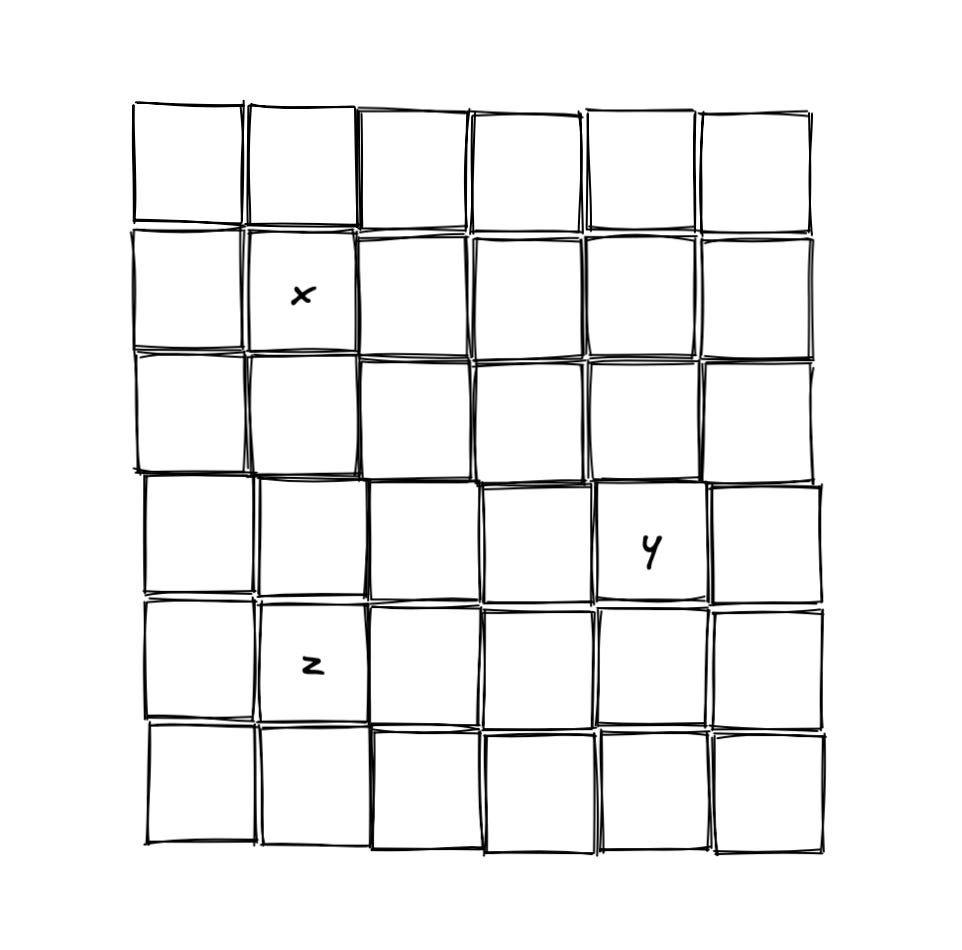
The first thing you’d realise is that we need a way to differentiate between x,y and z. This is commonly implemented in the form of an address, or the unique value that identifies a specific chunk of memory.
In python, we can get the location of a variable as seen below
>> x = 11
>>> id(2)
4304841504Note : You won’t get the same output when using Id. This is because the memory location will be allocated at run time for variables and is dependent on a host of all other factors that is out of scope for the article
In some languages, you might see this in the form of a pointer, which is really just a fancy name for a reference to a specific section of memory.
Variables
This brings us to our second important idea, that of a variable.
A variable is just a way for us to keep track of important values or in programming speak, pieces of state.
In python, we use variable names as a way for us to keep track of references. Let’s take the following example of a code that we are running.
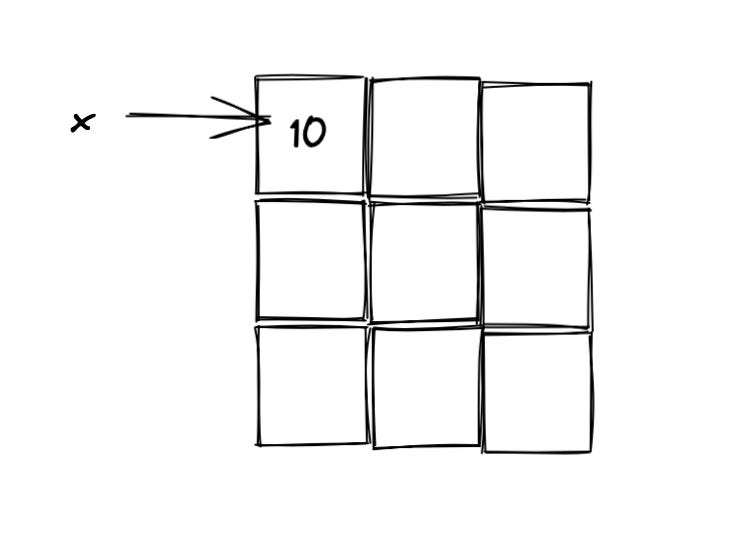
x = 10
print(id(x))
x = 12
print(id(x))In my case, this gives the output of
>>> x = 10
>>> print(id(x))
4321296912
>>> x = 12
>>> print(id(x))
4321296976If you look closely at what’s happening here, you’d notice that our pointer to the variable x has a different memory location when we reassign the value. Under the hood, this probably looks something like this.
First, we wrote the value of 10 to a place in memory. In this case, it can be uniquely identified by the value of 4321296912. We then initialised a variable called x that points to this specific memory address.
When we reassigned the value of 12 to x, this then resulted in two things happening. First, the new value of 12 was written into memory at some location. In this case, it was memory address 4321296976.

Next, we then modified x such that the pointer now points to this new memory address. Remember that under the hood, all that is happening is that we are updating the value that x points to with the new memory address. This then results in what we see below.

As such, this now results in the final outcome where x points to 12
Comparing Data Structures and Algorithms
This will deserve an entire walkthrough - with code at some point. But on a high level overview, when implementing data structures and algorithms, we care about two things.
The first is speed and the second is space.
Speed
When it comes to speed, this refers to the number of steps that needs to be executed by your program.
We always consider the worst case scenario when looking at time. Do keep that in mind as I go through the example.
Let’s see an example of how this might happen by examining two algorithms.
Say we wanted to find if there is a person called Samantha in the phone book where names are alphabetically ordered. This means that essentially, if your name begins with an A and your friend’s name begins with a Z, your name will be before his.
We could of course, simply look through the book, examining one name at a time. This is probably the slowest way to do so BECAUSE we are not exploiting the fact that the book is ordered.
At the same time, the number of steps we need to perform to accomplish the result we want is going to grow linearly with the number of names in the book.
In programming speak, this is referred to as O(n). If we have 400 people in the book, we will need to look through all the names for a total of 400 steps. If we have 40,000 people in the book, we will need to look through all the names for a total of 40,000 steps.
But, there’s a better way to do so, which is commonly known as Binary Search.
In this specific context, we know that since the names are ordered in an alphabetical manner, if we find a name beginning with an M and we are looking for someone that has a name beginning with a Z, we can avoid looking at all the names before an M.
In case it's not super obvious, we have effectively reduced the number of names that we would have to look through by a significant amount.
Let’s say we start with 400 people in the book, we would only need to look through a total of 8 people before we can conclude that the person does not exist. If we look through say 1600 people, we only need to look through a total of 11 people. ( Will go through this algorithm in a future post, it is not intuitive since it is exponential in nature )
Space
When it comes to working with algorithms, we also want those that help save space. This is a bit hard to illustrate without actual code but let’s compare two potential algorithms where we want to see if a value exists in a list.
Algorithm one does the following.
It first creates a list of the same size with no elements
It then copies over the elements from the list to this new list one at a time
If it finds the value we are looking for, it terminates and returns True. This indicates to us that the value exists in the array
def inefficient_algo(l,target):
new_list = [None]*len(l)
for index,element in enumerate(l):
if element == target:
return True
new_list[index] = element
return FalseAlgorithm two does the following
It looks at each element in the list one at a time
For each element, if it finds the value we are looking for, it terminates and returns True. This indicates to us that the value exists in the array.
def better_algo(l,target):
for element in l:
if element == target:
return True
return FalseWe can see already that algorithm one uses more space than algorithm two. This is because we allocate a new array that is the same size as the older one
In programming speak, we would say that algorithm one has a space-time complexity of O(n) while algorithm two has a space-time complexity of O(1).
In other words, for the same input of n elements, algorithm one will use n memory chunks (See above for working definition of memory) and algorithm two will use a constant amount ( that to store the pointer to the current element in the list we’re looking at ).
More concretely, for a input of 10 elements, algorithm one will use 10 memory chunks while algorithm two might use just 1. For an input of 2000 elements, algorithm one will use 2000 chunks while algorithm two might use just one again.
Conclusion
We didn’t cover much about specific data structures in this article and there’s a lot more ground to cover but I hope this gave some intuition as to why we might want to develop and learn more specialise algorithms and data structures.